| Journal |
|---|
| American Journal of International Law |
| Food Security |
| Journal of Business Economics and Management |
| Journal of Child Psychology and Psychiatry |
| Journal of Mathematics |
| Journal of the Association for Information Science and Technology |
| Nature Astronomy |
| Organic & Biomolecular Chemistry |
| Public Health |
| Solar Energy |
8 Topic Modelling
8.1 Learning objectives
- Tidytext
- Tokenization
- Stop words
- Sentiment analysis
- TF-IDF
- Topic modelling
8.2 Introduction
Text-mining could be a course of it’s own. This short introduction introduces a few of the most important concepts and provides examples of of to perform a range of text mining tasks. We will introduce a few new packages:
- tidytext: a package that contains a lot of function to work with text in a tidy format.
- textstem: to perform stemming and lemmatization on tokens
- wordcloud2: to make word clouds
- vader: to perform sentiment analysis
- topicmodels: to do topic modelling
8.3 The dataset
The dataset that we will use in this chapter consists of the the abstracts of 1672 open access scientific articles published between 2019 and 2020 in 10 journals from different fields of research.
The dataset is available here, or can loaded into R directly from the URL like this:
abstracts <- read_tsv("https://pmongeon.github.io/info6270/files/abstracts.txt") %>%
filter(journal %in% c("A","B","C","D"))8.4 Data formats for text mining
The two formats that we will consider in this chapter ar the tidy text format and the document-term matrix. Let’s start with a tibble that contain 2 documents with their text.
| Document | Text |
|---|---|
| A | I love bananas |
| B | I hate potatoes |
8.4.1 Tidy text
The tidy text format follows the same tidy principles that were introduced earlier in the course. It simply means that each row contains one token. A token is a meaningful units of text. Most often the tokens are individual words, but they can be sentences, paragraphs, groups of characters or words of a fixed length n (also known as n-grams), etc.
In principle the tibble above with the text of our two documents is already in a tidy text format where each row is a meaningful unit of text (the token, here would be the entire text). But if we chose words as our tokens, then it would look like this:
| document | words |
|---|---|
| A | i |
| A | love |
| A | bananas |
| B | i |
| B | hate |
| B | potatoes |
8.4.2 Document-term matrix
Document-term matrices contain all documents in a set as rows and all tokens as columns. The cells typically containing the frequency of the term in the document. Here is a document-term matrix for our two documents
| bananas | hate | i | love | potatoes | |
|---|---|---|---|---|---|
| A | 1 | 0 | 1 | 1 | 0 |
| B | 0 | 1 | 1 | 0 | 1 |
The topicmodels package requires data to be formatted in a document-term matrix, but all the other tasks that we will perform in the rest of the chapter are working with the tidy text format.
8.5 Tokenizing
Tokenizing is the process of dividing the text of our documents in our chosen unit. The unnest_tokens() function of the tidytext package can be used for task. Three main arguments are required:
- output: the name of the column that will contain the tokens.
- input: the name of the column that currently contain the text.
- token: the desired type of token (possible values are “words”,“sentences”, “ngrams”)
- n: this specifies the value of n for n-grams.
Note that you could perform write a code that does the exact same thing as the unnest_tokens() function with the set of functions that you learned in chapter 3 and 4. The unnest_tokens() function simply makes that code much, much more efficient.
8.5.1 Words
The following code divides the abstract into individual words with token = "words" .
abstracts_words <- abstracts %>%
unnest_tokens(output = word,
input = abstract,
token = "words")
head(abstracts_words) %>%
kbl() %>%
kable_classic()| id | journal | word |
|---|---|---|
| 1 | A | parenting |
| 1 | A | behaviors |
| 1 | A | have |
| 1 | A | been |
| 1 | A | shown |
| 1 | A | to |
8.5.2 Sentences
You can tokenize by sentence with token = "sentences".
abstracts_sentences <- abstracts %>%
unnest_tokens(output = sentence,
input = abstract,
token = "sentences")
head(abstracts_sentences) %>%
kbl() %>%
kable_classic()| id | journal | sentence |
|---|---|---|
| 1 | A | parenting behaviors have been shown to moderate the association between sensation seeking and antisocial behaviors. |
| 1 | A | data were obtained from the boricua youth study, a longitudinal study of 2,491 puerto rican youth living in the south bronx, new york, and the metropolitan area of san juan, puerto rico. |
| 1 | A | first, we examined the prospective relationship between sensation seeking and antisocial behaviors across 3 yearly waves and whether this relationship varied by sociodemographic factors. |
| 1 | A | second, we examined the moderating role of parenting behaviors-including parental monitoring, warmth, and coercive discipline-on the prospective relationship between sensation seeking and antisocial behaviors. |
| 1 | A | sensation seeking was a strong predictor of antisocial behaviors for youth across two different sociocultural contexts. |
| 1 | A | high parental monitoring buffered the association between sensation seeking and antisocial behaviors, protecting individuals with this trait. |
8.5.3 N-grams
You can tokenize by groups of words of size N with token = "ngrams" and the specifying how many words you want in each groups with n=N.
abstracts_bigrams <- abstracts %>%
unnest_tokens(output = bigram,
input = abstract,
token = "ngrams",
n = 2)
head(abstracts_bigrams) %>%
kbl() %>%
kable_classic()| id | journal | bigram |
|---|---|---|
| 1 | A | parenting behaviors |
| 1 | A | behaviors have |
| 1 | A | have been |
| 1 | A | been shown |
| 1 | A | shown to |
| 1 | A | to moderate |
For the rest of the chapter, we’ll use the abstracts_words tibble, in which our tokens are individual words.
8.6 Removing stop words
The English language is full of words that carry little to no meanings, and that tend to be the most frequent terms we use. To illustrate this, let’s look at the ten most frequent terms in the abstracts dataset.
| word | n |
|---|---|
| the | 5626 |
| of | 4463 |
| and | 4049 |
| in | 2519 |
| to | 2427 |
| a | 1932 |
| with | 1217 |
| for | 1106 |
| that | 1087 |
| is | 893 |
We can see that the dataset is dominated by terms that don’t carry much meaning, such as “a”, “of”, “the”, and “and”. These are called stop words and, fortunately, the tidytext package includes a a dataset called stop_words that we can use to eliminate these words from our data. Let’s look at a few rows from the stop_words dataset.
head(stop_words) %>%
kbl() %>%
kable_classic()| word | lexicon |
|---|---|
| a | SMART |
| a's | SMART |
| able | SMART |
| about | SMART |
| above | SMART |
| according | SMART |
We can use the anti_join() function to remove any row in a tibble that matches another tibble on a specified variable. In this case, we want to remove all the words that are in the stop_words tibble.
abstracts_words <- abstracts_words %>%
anti_join(stop_words, by="word")If we take a look at the most frequent terms again, we see that most of those little meaningless words are gone.
abstracts_words %>%
count(word, sort = TRUE) %>%
top_n(10) %>%
kbl() %>%
kable_classic()| word | n |
|---|---|
| food | 555 |
| children | 292 |
| study | 267 |
| symptoms | 266 |
| 1 | 248 |
| age | 230 |
| adhd | 215 |
| risk | 208 |
| data | 207 |
| 2 | 179 |
8.7 Stemming and lemmatization
The next issue that we typically face with text mining is the presence of word variations that are considered distinct tokens. These variation can include plural and singular terms, verb conjugations, etc. Here is an example of a set of tokens from our dataset.
| word |
|---|
| study |
| studies |
| students |
| student |
| study's |
| studied |
| understudied |
| studying |
Stemming and lemmatization are two ways of normalizing words by reducing words to their base called stem and lemma, respectively. Here are the stems and the lemmas of the words containing the string “stud”.
| word | stem | lemma |
|---|---|---|
| study | studi | study |
| studies | studi | study |
| students | student | student |
| student | student | student |
| study's | study' | study's |
| studied | studi | study |
Understanding how stemming and lemmatization works is beyond the scope of this course, but you should know that:
both methods work well for eliminating the plural form.
Stems are not always an actual word but the root of a word (ex. “moder” is the stem of “moderate”), while Lemmas are always actual words.
Stemming usually produces a lower number of unique words than than lemmatization.
We can easily add the stem and the lemma of words in our tibble using the stem_words() and lemmatize_words() functions from the textstem package, which also includes stem_strings() and lemmatize_strings() functions when dealing with tokens that are more than one word.
For this chapter, I will use the lemmatization to normalize my words. I do so by replacing my words with their lemma with the following code.
library(textstem)
abstracts_words <- abstracts_words %>%
mutate(word = lemmatize_words(word))
head(abstracts_words, n=10) %>%
kbl() %>%
kable_classic() | id | journal | word |
|---|---|---|
| 1 | A | parenting |
| 1 | A | behavior |
| 1 | A | show |
| 1 | A | moderate |
| 1 | A | association |
| 1 | A | sensation |
| 1 | A | seek |
| 1 | A | antisocial |
| 1 | A | behavior |
| 1 | A | datum |
8.8 Term frequency
A first exploration of our data is to calculate the frequency of each terms for the whole set of documents, for each journals, and for each individual document.
8.8.1 Overall term frequency
abstracts_words %>%
count(word, sort = TRUE) %>%
top_n(20) %>% # same has head(n=20)
kbl() %>%
kable_classic()| word | n |
|---|---|
| food | 584 |
| child | 441 |
| study | 375 |
| age | 316 |
| model | 303 |
| report | 295 |
| star | 293 |
| symptom | 293 |
| system | 293 |
| 1 | 248 |
| low | 239 |
| risk | 228 |
| adhd | 215 |
| increase | 208 |
| datum | 207 |
| household | 201 |
| mass | 201 |
| effect | 199 |
| measure | 198 |
| result | 194 |
8.8.2 Term frequency by journal
abstracts_words %>%
group_by(journal) %>%
count(word, sort = TRUE) %>%
slice(1:8) %>%
ggplot() +
aes(x=n, y=reorder(word,n)) +
geom_col() +
facet_wrap(facet = ~journal,
ncol=2,
scale="free") +
theme_minimal() +
labs(y = "Word", x="Frequency") +
scale_y_reordered()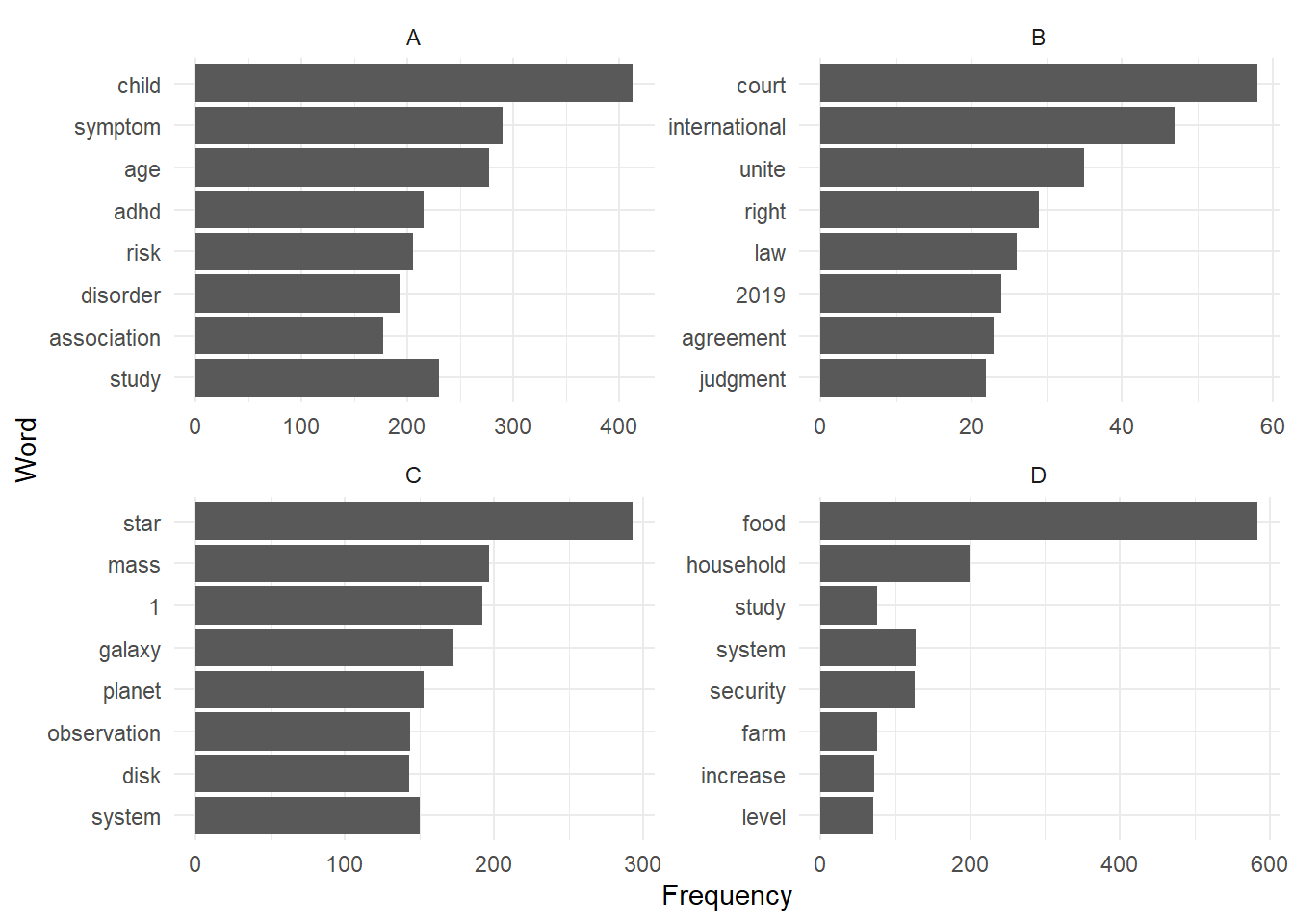
8.8.3 Term frequency by document
abstracts_words %>%
filter(id <= 4) %>% # I select papers with ID 1 to 4
group_by(id) %>% # I chose the papers as my unit of analysis
count(word,
sort = TRUE) %>%
slice(1:8) %>% # get the 8 most frequent terms for each document
ggplot() +
aes(x = n,
y = reorder(word, n)) +
geom_col() +
facet_wrap(facet = ~id, # here I use the papers_id for the facet
ncol=2,
scale="free") +
theme_minimal() +
labs(y = "Word", x = "Freqency")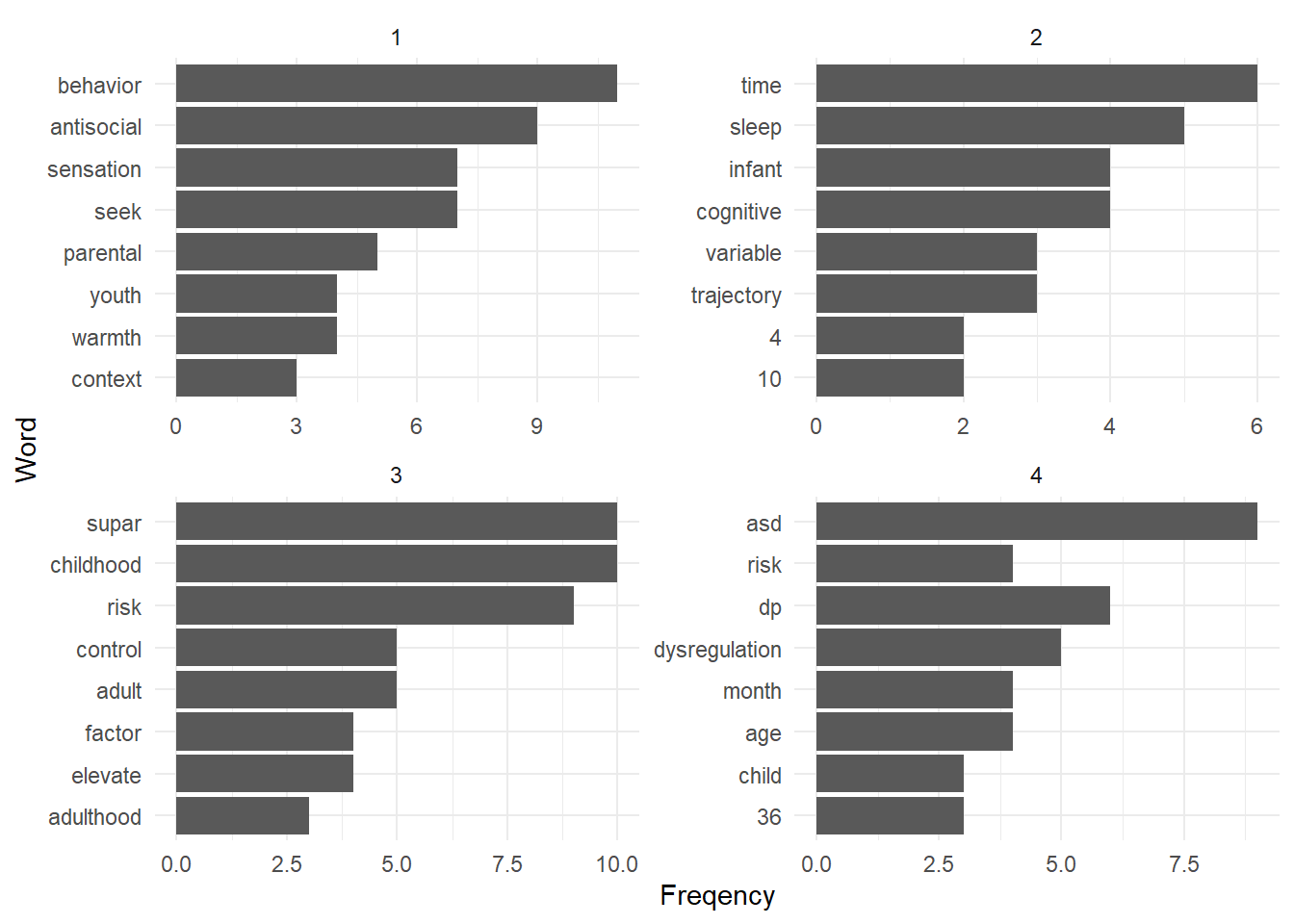
8.8.4 Word clouds
While word clouds are not more informative than term frequency tables, they are a space-efficient means to show a larger number of words and their relative frequency in a set. the wordcloud and wordcloud2 packages can be used to generate word clouds. Let’s look at the word cloud for the 100 most frequent terms for each journal.
library(wordcloud2)
abstracts_words %>%
filter(journal == "A") %>%
count(word, sort=TRUE) %>% # adds a column n with the frequency of the word.
slice(1:100) %>%
wordcloud2(size = 0.3, # Size of the text (default is 1)
minRotation = -pi/2, # Min roation is 90 degrees
maxRotation = -pi/2, # Max rotation is 90 degrees
rotateRatio = 0, # percentage of words to rotate (none, in this case)
shape = "circle",
color="black")
library(wordcloud2)
abstracts_words %>%
filter(journal == "B") %>%
count(word, sort=TRUE) %>% # adds a column n with the frequency of the word.
slice(1:100) %>%
wordcloud2(size = 0.3, # Size of the text (default is 1)
minRotation = -pi/2, # Min roation is 90 degrees
maxRotation = -pi/2, # Max rotation is 90 degrees
rotateRatio = 0, # percentage of words to rotate (none, in this case)
shape = "circle",
color="black")
library(wordcloud2)
abstracts_words %>%
filter(journal == "C") %>%
count(word, sort=TRUE) %>% # adds a column n with the frequency of the word.
slice(1:100) %>%
wordcloud2(size = 0.3, # Size of the text (default is 1)
minRotation = -pi/2, # Min roation is 90 degrees
maxRotation = -pi/2, # Max rotation is 90 degrees
rotateRatio = 0, # percentage of words to rotate (none, in this case)
shape = "circle",
color="black")
library(wordcloud2)
abstracts_words %>%
filter(journal == "D") %>%
count(word, sort=TRUE) %>% # adds a column n with the frequency of the word.
slice(1:100) %>%
wordcloud2(size = 0.5, # Size of the text (default is 1)
minRotation = -pi/2, # Min roation is 90 degrees
maxRotation = -pi/2, # Max rotation is 90 degrees
rotateRatio = 0, # percentage of words to rotate (none, in this case)
shape = "circle",
color="black")
As you can see, the word clouds give us a pretty good idea of what fields the journal included in the dataset may be from.
8.8.5 TF-IDF
TF-IDF stands for term frequency * inverse document frequency. Essentially, it measures how important (frequent) a term is in a document, and how rare that term is in the corpus. The result is a value between 0 and 1. The highest the tf-idf value, the more the term is specific to a document and therefore indicative of its specific topic.
abstracts_words <- abstracts_words %>%
group_by(id) %>%
count(word, sort=TRUE) %>%
bind_tf_idf(term = word,
document = id,
n = n)Let’s look at the most important words in a set of 9 nine articles. These are the words with the highest tf-idf values.
abstracts_words %>%
filter(id <= 9) %>%
group_by(id) %>%
top_n(8) %>%
ggplot() +
aes(x=tf_idf, y=reorder(word, tf_idf)) +
geom_col(show.legend = FALSE) +
facet_wrap(~id, ncol = 3, scales = "free") +
labs(y = "Word")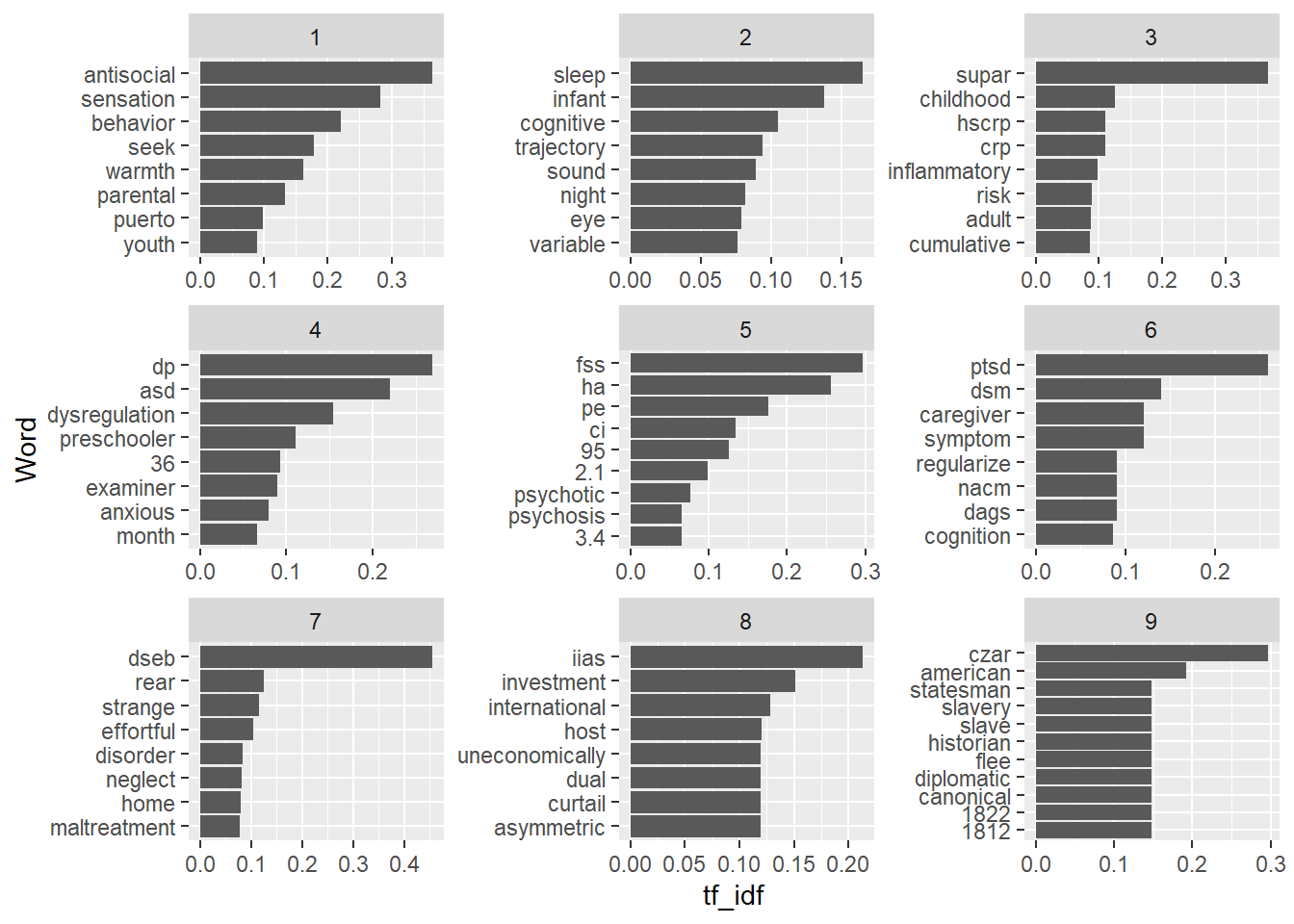
abstracts_words %>%
filter(id <= 9) %>%
group_by(id) %>%
top_n(8) %>%
ggplot() +
aes(x=n, y=reorder(word, n)) +
geom_col(show.legend = FALSE) +
facet_wrap(~id, ncol = 3, scales = "free") +
labs(y="Word")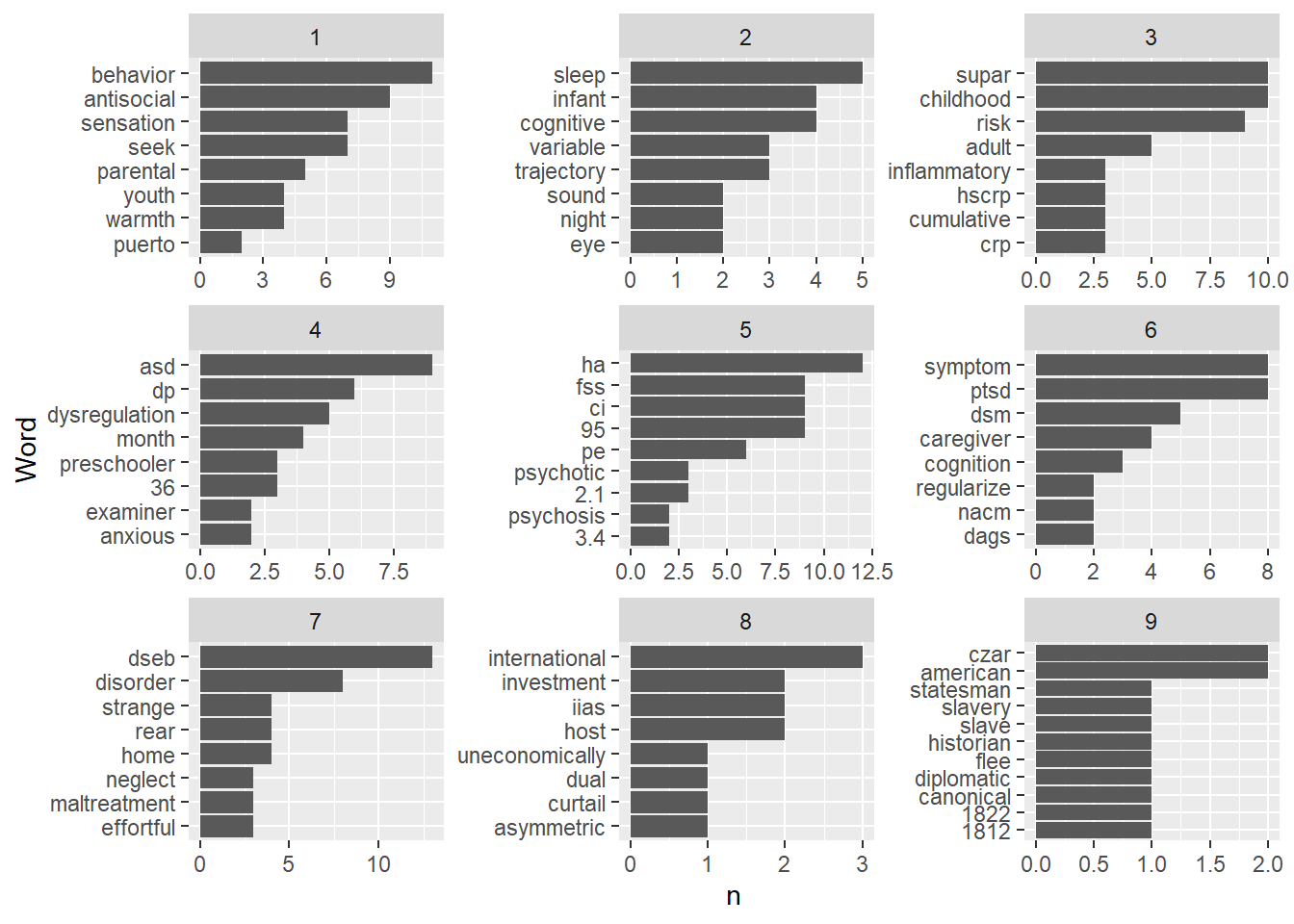
## Sentiment analysis
As the name suggest, sentiment analysis is a technique use to identify sentiment in text. The most basic sentiment analysis methods use list of terms with an associated sentiment (positive or negative) or a numerical value representing the strength or the sentiment: -2 (very negative) to +2 (very positive), for instance. The tidytext package includes a few of those terms list with associated sentiments, which you can access with the get_sentiments() function. The following example import the bing list and the afinn list into two tibbles.
sentiment_bing <- get_sentiments("bing")
sentiment_afinn <- get_sentiments("afinn")Let’s take a look.
head(sentiment_bing) %>%
kbl() %>%
kable_classic()| word | sentiment |
|---|---|
| 2-faces | negative |
| abnormal | negative |
| abolish | negative |
| abominable | negative |
| abominably | negative |
| abominate | negative |
head(sentiment_afinn) %>%
kbl() %>%
kable_classic()| word | value |
|---|---|
| abandon | -2 |
| abandoned | -2 |
| abandons | -2 |
| abducted | -2 |
| abduction | -2 |
| abductions | -2 |
We can then assign a sentiment to the words in our abstracts with the left_join() function that we introduced in chapter 3. Let’s use the afinn list for this example.
abstracts_words <- abstracts_words %>%
left_join(sentiment_afinn, by="word")
head(abstracts_words) %>%
kbl() %>%
kable_classic()| id | word | n | tf | idf | tf_idf | value |
|---|---|---|---|---|---|---|
| 10 | ccbt | 20 | 0.0847458 | 6.228511 | 0.5278399 | NA |
| 1276 | yield | 19 | 0.1210191 | 2.932674 | 0.3549096 | NA |
| 1598 | food | 19 | 0.1043956 | 1.706722 | 0.1781743 | NA |
| 244 | sct | 18 | 0.1011236 | 6.228511 | 0.6298494 | NA |
| 256 | anxiety | 18 | 0.1208054 | 2.794524 | 0.3375935 | -2 |
| 20 | sleep | 17 | 0.0949721 | 3.589454 | 0.3408978 | NA |
Now let’s just sum the score for each abstract to have a single sentiment score for each article, and order abstracts from the highest sentiment score to the lowest.
abstracts_sentiment <- abstracts_words %>%
group_by(id) %>%
summarize(sentiment = sum(value, na.rm=TRUE)) %>%
arrange(desc(sentiment))And then let’s look at the most positive abstracts and the most negative abstracts with head() and tail().
abstracts_sentiment %>%
inner_join(abstracts, by="id") %>%
select(id, journal, abstract, sentiment) %>%
head()# A tibble: 6 × 4
id journal abstract sentiment
<dbl> <chr> <chr> <dbl>
1 1137 D Rwanda has experienced significant economic growth fo… 16
2 1284 D Assessing progress towards healthier people, farms an… 15
3 1138 D This paper concerns Drought-Tolerant Maize (DTM) and … 13
4 214 A Care for children and adolescents with psychosocial p… 12
5 1451 D Using survey dataset collected from nearly 9000 farme… 12
6 73 A BackgroundChildren in the UK go through rigorous teac… 11abstracts_sentiment %>%
inner_join(abstracts, by="id") %>%
select(id, journal, abstract,sentiment) %>%
tail()# A tibble: 6 × 4
id journal abstract sentiment
<dbl> <chr> <chr> <dbl>
1 174 A "Suicide is the second leading cause of death in youn… -14
2 1598 D "This opinion article results from a collective analy… -14
3 248 A "Only one-third of young people who experience suicid… -15
4 1532 D "Children who experience poor nutrition during the fi… -16
5 50 A "Children with developmental disabilities are at heig… -21
6 320 A "Post-traumatic stress disorder (PTSD) is a common re… -22Let’s compare the average sentiment for the two journals in the dataset
abstracts_sentiment %>%
inner_join(abstracts, by="id") %>%
select(id, journal, abstract, sentiment) %>%
group_by(journal) %>%
summarize(mean_sentiment = mean(sentiment)) %>%
kbl() %>%
kable_classic()| journal | mean_sentiment |
|---|---|
| A | -2.268293 |
| B | -1.404255 |
| C | 2.010638 |
| D | 1.527778 |
8.8.5.1 The vader package
Valence Aware Dictionary and sEntiment Reasoner (VADER) is a popular sentiment analysis tool, that takes the context of words into account so that good (a positive term) can be interpreted as negative when it is preceded by the word not (as in “not good”).
You can calculate the sentiment and get a data frame with vader_df() function. This is an example for the first abstract in our dataset.
library(vader)
vader_df(abstracts$abstract[1]) text
1 Parenting behaviors have been shown to moderate the association between sensation seeking and antisocial behaviors. Data were obtained from the Boricua Youth Study, a longitudinal study of 2,491 Puerto Rican youth living in the South Bronx, New York, and the metropolitan area of San Juan, Puerto Rico. First, we examined the prospective relationship between sensation seeking and antisocial behaviors across 3 yearly waves and whether this relationship varied by sociodemographic factors. Second, we examined the moderating role of parenting behaviors-including parental monitoring, warmth, and coercive discipline-on the prospective relationship between sensation seeking and antisocial behaviors. Sensation seeking was a strong predictor of antisocial behaviors for youth across two different sociocultural contexts. High parental monitoring buffered the association between sensation seeking and antisocial behaviors, protecting individuals with this trait. Low parental warmth was associated with high levels of antisocial behaviors, regardless of the sensation seeking level. Among those with high parental warmth, sensation seeking predicted antisocial behaviors, but the levels of antisocial behaviors were never as high as those of youth with low parental warmth. Study findings underscore the relevance of person-family context interactions in the development of antisocial behaviors. Future interventions should focus on the interplay between individual vulnerabilities and family context to prevent the unhealthy expression of a trait that is present in many individuals.
word_scores
1 {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.15, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -0.55, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1.65, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -0.9, 0, 0, 0, 0, 0.15, 0, -3.6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
compound pos neu neg but_count
1 0.153 0.058 0.896 0.047 18.9 Topic modelling
In this section we will use a very common topic modelling technique called Latent Dirichlet Allocation (LDA). It is a dimensionality reduction technique that takes groups a large number of documents into a smaller number of topics.
abstracts_dtm <- abstracts_words %>%
cast_dtm(document = id, # name of the column with your document id
term = word, # name of the column with your tokens
value = n) # name of the column with your token frequencies8.9.1 Generate topic models
You can use the code below, and replace abstracts_dtm with the name of your document-term matrix object, and change the value of k to the number of topics that you want.
library(topicmodels)
abstracts_lda <- abstracts_dtm %>%
LDA(k = 4, # Number of topics desired
control = list(seed = 1234)) # Just leave this on as is8.9.2 Create a tidy text tibble with the topic-token association
The beta value is the strength of the association of a token with a topic. The higher the beta, the most strongly the term is associated to the topic.
topic_term_beta <- abstracts_lda %>%
tidy(matrix = "beta")topic_term_beta %>%
group_by(topic) %>%
slice_max(beta, n = 10) %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot() +
aes(x=beta, y=term) +
geom_col(show.legend = FALSE) +
facet_wrap(~topic, scales = "free") +
scale_y_reordered()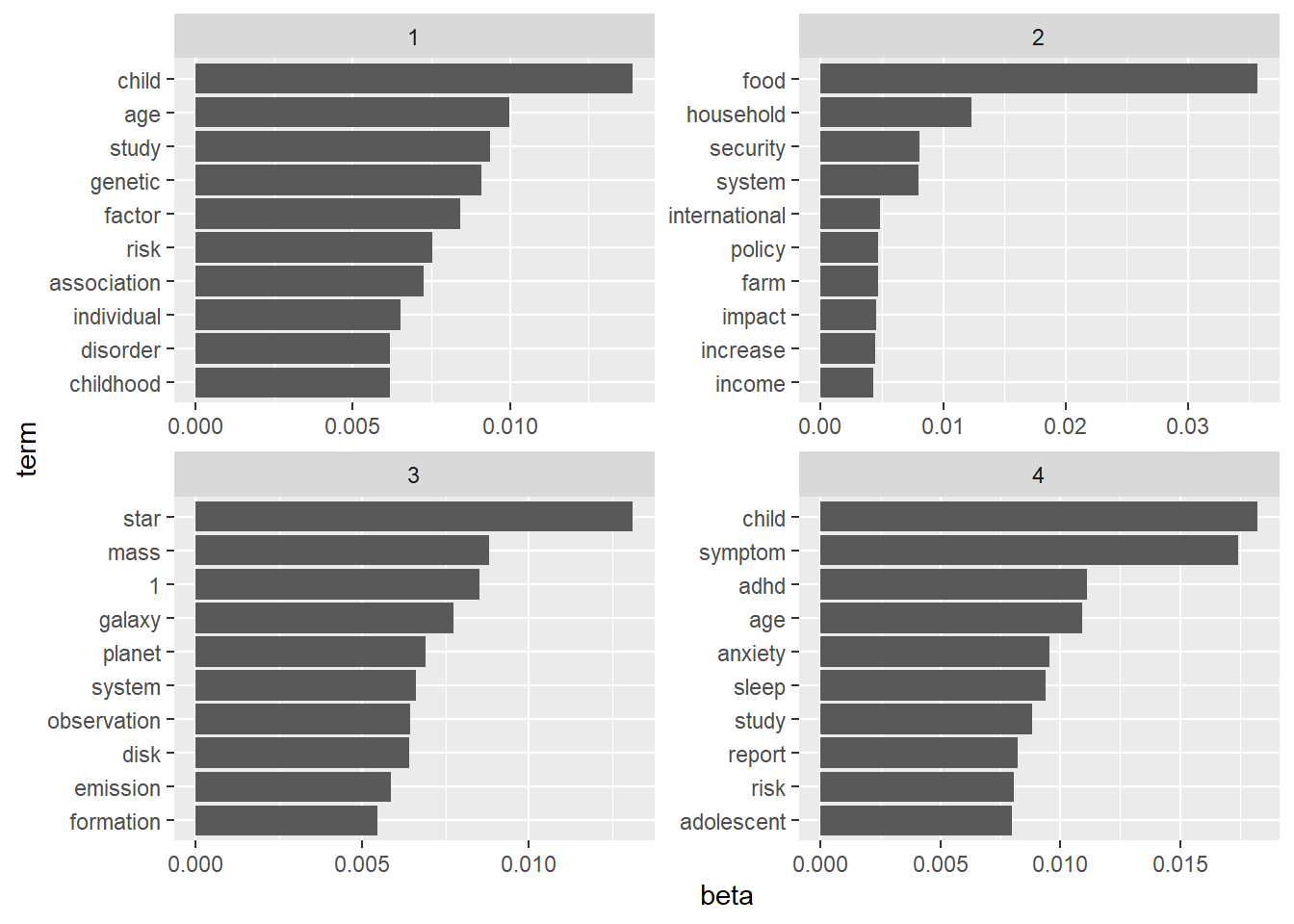
8.9.3 Create a tidy text tibble with abstract-topic association
The gamma value is the strength of the association of a document with a topic. The higher the beta, the most strongly the document is associated to the topic.
abstracts_topic <- abstracts_lda %>%
tidy(matrix = "gamma")abstracts_topic %>%
filter(as.numeric(document) <= 9) %>%
group_by(document) %>%
arrange(document, topic) %>%
ggplot() +
aes(x=gamma, y=reorder(topic, gamma)) +
geom_col(show.legend = FALSE) +
facet_wrap(~document, ncol = 3, scales = "free") +
labs(y="Topic")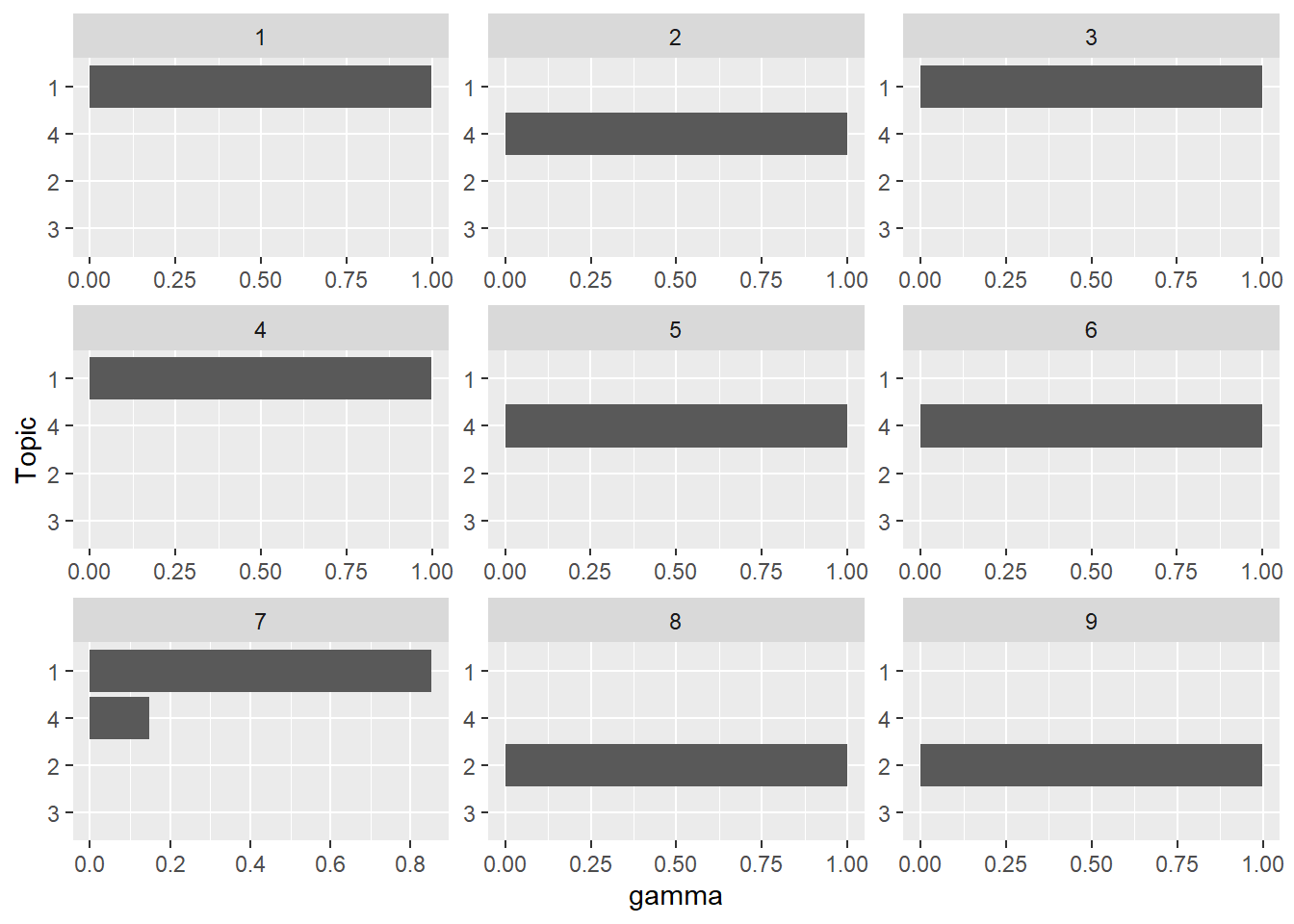
8.10 Other resources
Project gutenberg (https://www.gutenberg.org/) provides access to a large collection of free eBooks that can be downloaded in a plain text (.txt) format that is convenient for text-mining. the gutenbergr package allows you to search the project gutenberg collection and import books directly in R.
Text mining with R (https://www.tidytextmining.com/index.html) by Julia Silge and David Robinson is a great resource for beginners with lots of R examples. The book includes several examples that use the gutenbergr package.