4 Bibliometric data sources
4.1 Introduction
Bibliometric analyses are mainly based on the metadata of scholarly outputs. If we take the article below, the metadata would include the title, authors, author affiliations, abstract, acknowledgements, author contributions, and references. The other elements are part of the full text of the article and are not generally included in bibliometric databases and analyses. While there are researchers, databases, websites and service providers that do use the full-text of articles, they will not be the focus of the course, except for one (scite.ai) that we will discuss in chapter 7.

The vast majority of bibliographic databases that you will typically access through the university library, such as LISA (Library and Information Science Abstract) or PsycInfo, are mainly used for information retrieval. While they are technically able to support some level of bibliometric analyses, the possibilities are very limited.
The main advantages of most of the databases that we use for bibliometrics are:
They index more metadata elements from the paper
They enrich the metadata by adding things like disciplinary classifications, unique identifiers for authors and other entities, etc.
They index citations: this is why these databases are often called citation indexes. (or scientific knowledge graph (SKG), which may be a better name since these databases generally include more than citations).
The indexing of citations, pioneered by Eugene Garfield in the 1960s, is the key innovation that led to the emergence and growth of bibliometrics as its own field of research over the last half-century. This chapter presents some of the main citation indexes that are available today and that support research evaluation and bibliometric research across the globe.
4.2 Web of Science
The Web of Science is the oldest bibliometric database. It was created in 1963 by Eugene Garfield and his company, the Institute for Scientific Information (ISI). It took 33 years before a competitor emerged (Scopus). In fact, the Web of Science is a collection of citation indexes. The main ones generally used in bibliometric research are the Science Citation Index Expanded (SCIE), the Social Sciences Citation Index (SSCI), and the Arts & Humanities Citation Index (AHCI).
Because it’s been around so long, the Web of Science (and because Elsevier was not making its database available for large-scale research until very recently) the Web of Science has long been the main database used for large scale bibliometric studies.
Its main advantages are its long coverage period (although the competitors are catching up), the consistency of its metadata, and the clear criteria for the inclusion of sources in the database. (you can read about the editorial selection process here). However, the Web of Science’s focus on quality and consistency makes it one of the databases with the lowest coverage among its competitors.
If you’re interested in what a citation index looked like before the internet, I recommend the three videos below, produced by the ISI in 1967.
Unfortunately, the Dalhousie Libraries do not have a subscription to the Web of Science, so you will not be able to use it as a data source for the course.
4.3 Elsevier’s suite: Scopus, SciVal, and the ICSR lab.
4.3.1 Scopus
Elsevier launched Scopus in 1996 as the first competitor for the Web of Science for information retrieval purposes. Unlike the Web of Science, which made its raw data available for research (although not for free) for decades, Scopus data was for a long time only available through a subscription to its web platform (which only allows you to download 2000 records at a time and makes large scale bibliometric analyses difficult if not impossible).
There is no free access to Scopus, but you can access Scopus through the Dalhousie libraries.
4.3.2 SciVal
Scival uses the same data as Scopus, but it is designed for research evaluation purposes. You can also access SciVal through the Dalhousie Libraries (Note: you will need to create an account and log in to use SciVal).
The good thing about SciVal is that it provides an interface that you can use to calculate a variety of indicators, produce rankings, visualize trends, etc. However, the interface can be a little confusing and clunky. It can also lead you to use whatever indicator or visualization the platform provides rather than other indicators and visualizations that may fit your needs better.
4.3.3 International Center for the Study of Research (ICSR) Lab
Possibly in an attempt to compete with the Web of Science, and especially with Dimensions (see below), which are offering access to their full database to research, Elsevier recently launched the International Center for the Study of Research (ICSR) Lab. The lab allows researchers to submit research proposals and get access to their data infrastructure. (details here: https://elsevier.international/icsr.html).
4.4 Dimensions
Dimensions is a relatively new player. It is a database like Web of Science and Scopus developed by a company called Digital Science, which happens to be owned by another large publishing company: Springer-Nature. Unlike Web of Science and Scopus, which are accessible via subscription only (and they are not cheap!), Dimensions has a free online search interface that provides access to its publication data (which is great because that is what you’ll need 95% of the time).
Again, this search engine is mostly useful for information retrieval. However, Like Scopus and Web of Science, it is possible for researchers to submit research proposals and get access to the full data infrastructure for research.
4.5 Crossref
Crossref is a non-profit organization run by the Publishers International Linking Association (PILA). It is also a major Digital Object Identifier (DOI) registration agency. Crossref’s main focus is on creating an open and free database of linking research objects (articles, books, datasets, etc.). However, its search engine is not very good, and Crossref is usually not the best choice for searching the literature.
That said, Crossref provides free access to its entire database through its application programming interface (API) and the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). Crossref also makes the entire Crossref database available for download (don’t do it. It’s huge). Details here.
4.6 OpenAlex
OpenAlex is a new and entirely open platform managed by a non-profit organization called OurResearch. At the core of OpenAlex is the Microsoft Academic Graph (MAG), an open database that Microsoft stopped supporting in 2021, as well as Crossref, but OpenAlex also includes data from a variety of other sources in an attempt to provide the most comprehensive, fully open database of scholarly entities and outputs. Here is the OpenAlex database schema:
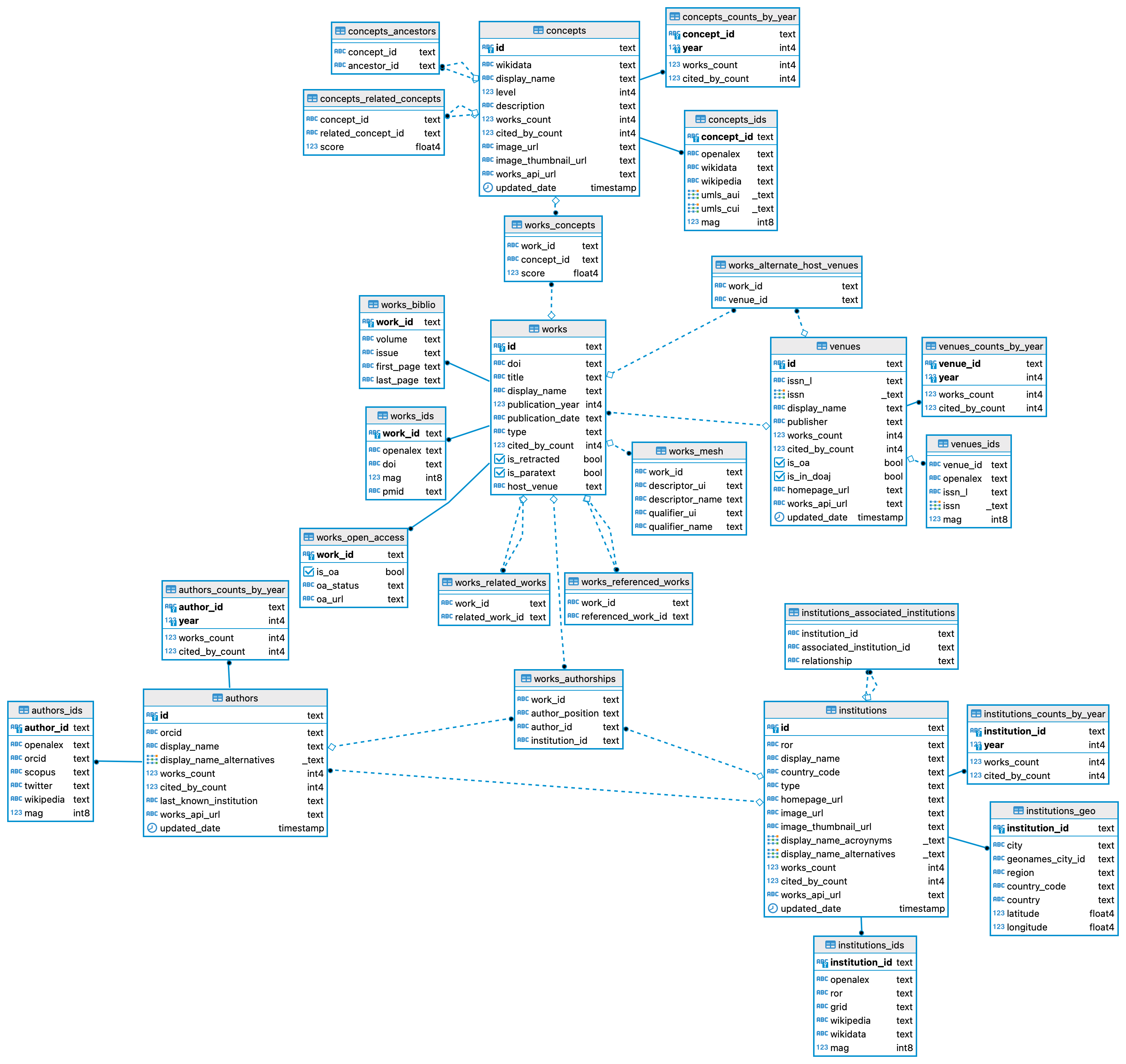
On top of its web search engine, OpenAlex has a free API, and the entire database can also be downloaded for free (don’t do it, it’s huge).
4.7 Google Scholar
Google Scholar (https://scholar.google.ca/) has the best coverage of all databases. Unlike databases like Scopus and Web of Science which index specific journals that meet some criteria, Google Scholar crawls the web and collects everything that Google robots consider to be a scholarly output. This may be good for coverage, but at the expense of some data quality issues. Google Scholar has many shortcomings, some as direct results of its lack of selection criteria:
The Google Scholar process is a black box. We do not have a list of included sources or know how the robots are doing the indexing.
Data is not easy to access and download for analysis.
The metadata is much more limited than in other databases.
Limited data extraction capabilities.
4.7.1 Google Scholar profiles
Researchers’ profiles on Google Scholar is one of the most powerful and useful feature of the site. One of the reasons is that most researchers take ownership of their Google Scholar profile, verify it, and curate it. Thus, verified Google Scholar profiles are one of the best way to avoid the challenge of author name disambiguation, which we will discuss in more detail in Chapter 6.
This is a screenshot of a Google Scholar profile (and this is the URL: https://scholar.google.ca/citations?user=wvX4S8sAAAAJ)
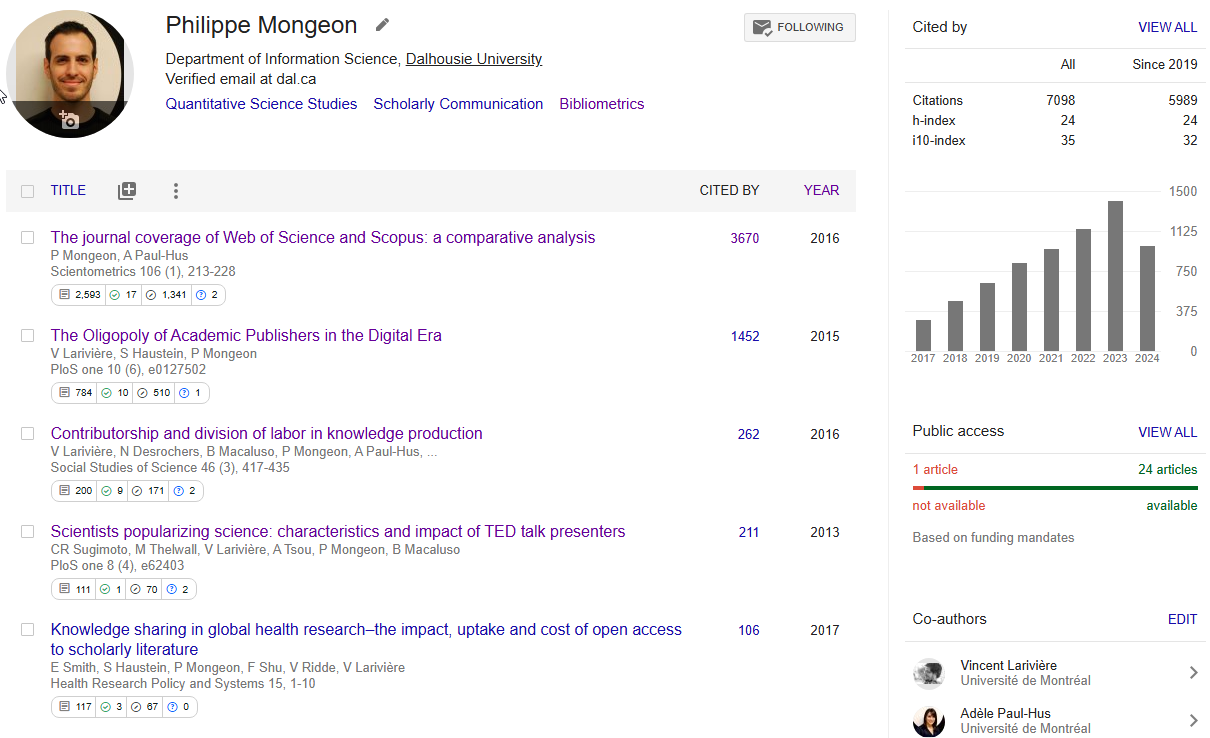 This is all nice, but we’re still not able to easily collect the data for some analysis. There is free software for this called Publish or Perish that can help, but its capacities are also quite limited. In chapter 6, a short demo will be provided to show how to make effective use of publish or perish to collect publications and citation data for individual researchers.
This is all nice, but we’re still not able to easily collect the data for some analysis. There is free software for this called Publish or Perish that can help, but its capacities are also quite limited. In chapter 6, a short demo will be provided to show how to make effective use of publish or perish to collect publications and citation data for individual researchers.
4.8 How to choose a data source?
You should always, always start with some idea of what your goal is and what data you need to achieve that goal. So the first question is:
- What is the goal of my analysis? What do I want to know?
Once you know what you want to know, then you are ready to ask the second most important question:
- What data do I need to know what I want to know?
The point is that some databases may be more generous than others in terms of metadata elements and the possibilities they offer, but that will not help you if you don’t need those extra features. In other words, you don’t want the best database. You want the best database for your needs. So start by identifying what those needs are.
Then you can start exploring the databases and ask the questions below to help you guide your decision.
What metadata does the database provide?
Does it include author identifiers to help with disambiguation?
Does it include all the author’s institutional addresses?
Does it include all cited sources?
Does it include the abstract?
Does it include the authors’ keywords?
Does it include funding acknowledgements?
Does it include some disciplinary classification?
Etc.
How easily accessible is the data?
Can I easily download all the data I will need for my analysis?
What interface/methods are available to retrieve data?
Can I retrieve that data in a format that I know how to use?
How structured is the data?
Will I have to do a lot of data processing?
Do I have the skills to do that data processing?
Does the database adequately cover the field/countries/languages I want to analyze?
- Some databases cover non-English research and certain disciplines like Arts & Humanities better than others.
If you’re working on a small scale (trying to build a comprehensive database of a person or a small unit’s research output, you might want to combine multiple databases to achieve the best results.
4.9 What skills do I need to do this?
No, you do not need to know any programming languages like SQL, R or Python to do bibliometrics. There are plenty of free tools that can help you, and most data processing and analyses can be done in Excel too. That said, programming skills definitely can help you perform more complex tasks, use a broader range of databases, or just save time with data collection, cleaning, processing and analysis.
In this course, you are free to choose whatever tool you wish to use. Your instructor will be there to help no matter what choices you make, so don’t be afraid to challenge yourself.
4.10 Further readings
If you are curious, you can check out this recent study that compared some of the databases mentioned in this chapter:
Visser, M., van Eck, N. J., & Waltman, L. (2021). Large-scale comparison of bibliographic data sources: Scopus, Web of Science, Dimensions, Crossref, and Microsoft Academic. Quantitative Science Studies, 2(1), 20–41. https://doi.org/10.1162/qss_a_00112